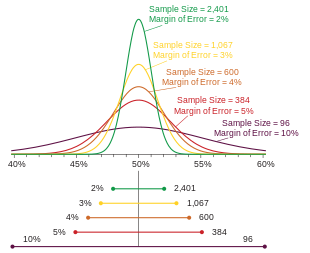
Hustoty pravděpodobnosti hlasování různých velikostí, z nichž každá je barevně odlišena na 95%
interval spolehlivosti (níže), rozpětí chyby (vlevo) a velikost vzorku (vpravo). Každý interval odráží rozsah, ve kterém je možné mít 95% jistotu, že lze nalézt
skutečné procento, vzhledem k uvedenému procentu 50%.
Tolerance chyb je polovina je interval spolehlivosti (také je
poloměr intervalu). Čím větší je vzorek, tím menší je chyba. Také, čím dále od 50% hlášeného procenta, tím menší je chybovost.
Tolerance chyb je statistika, vyjadřující množství náhodné výběrové chyby ve výsledcích průzkumu . Čím větší je chybovost, tím menší jistotu by měl mít člověk, že výsledek hlasování bude odrážet výsledek průzkumu celé populace . Hranice chyby bude kladná, kdykoli je populace neúplně odebrána a výsledná míra má pozitivní rozptyl , to znamená, že se míra liší .
Termín mez chyby se často používá v kontextech bez průzkumu k označení pozorovací chyby při vykazování měřených veličin. To je také používáno v hovorové řeči se odkazovat na množství prostoru nebo množství flexibility jeden mohl mít při dosahování cíle. Například jej ve sportu často používají komentátoři při popisu, jak velká přesnost je zapotřebí k dosažení cíle, bodů nebo výsledku. Bowling pin používá ve Spojených státech je 4,75 palce široký, a míč je 8,5 palce široký, takže by se dalo říci, nadhazovač má 21,75 palce toleranci chyb při pokusu zasáhnout konkrétní pin vydělat extra (například 1 pin zbývající na jízdním pruhu).
Pojem
Vezměme si jednoduchý ano / ne hlasování jako vzorek respondentů čerpaných z populace vykazujících procento z ano odpovědí. Chtěli bychom vědět, jak blízko je skutečný výsledek průzkumu celé populace , aniž bychom jej museli provádět. Pokud bychom hypoteticky provedli průzkum nad následujícími vzorky respondentů (nově získanými od ), očekávali bychom, že tyto následné výsledky budou normálně distribuovány . Tolerance chyb popisuje vzdálenost, ve které se očekává, že specifikované procento těchto výsledků, které se liší od .







Podle pravidla 68-95-99.7 bychom očekávali, že 95% výsledků bude spadat do přibližně dvou standardních odchylek ( ) na obě strany skutečného průměru . Tento interval se nazývá interval spolehlivosti a poloměr (polovina intervalu) se nazývá okraj chyby , což odpovídá 95% úrovni spolehlivosti .

Obecně platí, že na úrovni spolehlivosti má vzorek velikosti populace s očekávanou standardní odchylkou rezervu chyb



kde označuje kvantil (obvykle také z-skóre ) a je standardní chybou .


Standardní odchylka a standardní chyba
Očekávali bychom, že normálně distribuované hodnoty budou mít standardní odchylku, která se nějak mění s . Čím menší , tím širší okraj. Tomu se říká standardní chyba .

U jediného výsledku našeho průzkumu předpokládáme, že a že všechny následující výsledky společně budou mít odchylku .



Všimněte si, že to odpovídá rozptylu Bernoulliho distribuce .

Maximální chybovost při různých úrovních spolehlivosti
Pro úroveň spolehlivosti existuje odpovídající interval spolehlivosti o průměru , tj. Interval, ve kterém by měly hodnoty s pravděpodobností klesat . Přesné hodnoty jsou dány kvantilovou funkcí normálního rozdělení (které pravidlo 68-95-99.7 přibližuje).

![{\ Displaystyle [\ mu -z _ {\ gamma} \ sigma, \ mu +z _ {\ gamma} \ sigma]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a4568060e0cffbc8dfb793aa2ef4617c89cb9e94)
Všimněte si, že je undefined for , to znamená, je undefined, as is .



|
|
|
|
|
|
| 0,68
|
0,994 457 883 210
|
0,999
|
3,290 526 731 492
|
| 0,90
|
1,644 853 626 951
|
0,9999
|
3,890 591 886 413
|
| 0,95
|
1.959963984540
|
0,99999
|
4,417 173 413 469
|
| 0,98
|
2,326 347 874 041
|
0,999999
|
4,891 638 475 699
|
| 0,99
|
2,575 829 303 549
|
0,9999999
|
5,326 723 886 384
|
| 0,995
|
2,807 033 768 344
|
0,99999999
|
5,730 728 868 236
|
| 0,997
|
2,967 737 925 342
|
0,999999999
|
6,109 410 204 869
|
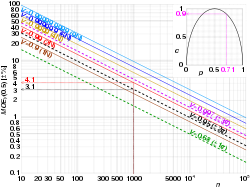
Protokolovejte grafy velikosti vs vzorku
n a úrovně spolehlivosti γ . Šipky ukazují, že maximální chyba okraje pro velikost vzorku 1000 je ± 3,1% při 95% úrovni spolehlivosti a ± 4,1% při 99%. Vložená parabola ilustruje vztah mezi at a at . V tomto případě MOE 95 (0,71) ≈ 0,9 × ± 3,1% ≈ ± 2,8%.





Vzhledem k tomu, v , můžeme libovolně nastavit , spočítat , a získat maximální toleranci chyb pro v dané hladině spolehlivosti a vzorkovací velikostí , a to i před tím, než se skutečné výsledky. S






Také užitečné pro všechny hlášené 

Specifické chyby
Pokud má hlasování více procentních výsledků (například hlasování měřící jednu preferenci s více možnostmi výběru), bude mít výsledek nejblíže 50% nejvyšší chybovost. Obvykle je to toto číslo, které je vykazováno jako rezerva chyby pro celý průzkum. Představte si, že ankety zprávy jsou

-
 (jako na obrázku výše)
(jako na obrázku výše)


Jak se dané procento blíží extrémům 0%nebo 100%, jeho chyba se blíží ± 0%.
Srovnání procent
Představte si, že multiple-choice poll zprávy jsou . Jak je popsáno výše, tolerance chyb hlášeny pro hlasování by obvykle bylo , jak je nejblíže k 50%. Populární pojem statistické kravaty nebo statistického mrtvého tepla se však netýká přesnosti jednotlivých výsledků, ale pořadí výsledků. Který je v prvním?



Pokud bychom hypoteticky provedli průzkum nad následujícími vzorky respondentů (nově získanými od ) a oznámili výsledek , mohli bychom použít standardní chybu rozdílu, abychom pochopili, jak se očekává pokles . K tomu musíme použít součet rozptylů, abychom získali novou rozptyl ,





kde je kovariance o a .



Po zjednodušení tedy



Všimněte si, že to předpokládá, že se blíží k konstantě, to znamená, že respondenti si vybírá buď A nebo B se téměř nikdy vybral C (takže i v blízkém okolí je dokonale záporně koreloval ). Se třemi nebo více možnostmi v těsnějším souboji se stává výběr správného vzorce pro složitější.

Vliv konečné velikosti populace
Vzorce výše pro okraj chyby předpokládají, že existuje nekonečně velká populace, a proto nezávisí na velikosti populace , ale pouze na velikosti vzorku . Podle teorie odběru vzorků je tento předpoklad rozumný, když je odběrová frakce malá. Tolerance chyb pro určité metody odběru vzorků je v podstatě stejná bez ohledu na to, zda zkoumané populace je velikost školy, město, stát, nebo země, pokud je odběr frakce je malý.
V případech, kdy je část vzorku větší (v praxi větší než 5%), mohou analytici upravit rozpětí chyb pomocí konečné korekce populace, aby se zohlednila přidaná přesnost získaná vzorkováním mnohem většího procenta populace. FPC lze vypočítat pomocí vzorce

... a pokud by bylo provedeno hlasování více než 24%, řekněme, voličů s 300 000 voliči


Intuitivně, pro dostatečně velké ,


V prvním případě je tak malý, že nevyžaduje žádnou opravu. V druhém případě se hlasování skutečně stane sčítáním lidu a chyba vzorkování bude diskutabilní.
Viz také
Poznámky
Reference
- Sudman, Seymour a Bradburn, Norman (1982). Kladení otázek: Praktický průvodce návrhem dotazníku . San Francisco: Jossey Bass. ISBN 0-87589-546-8
-
Wonnacott, TH a RJ Wonnacott (1990). Úvodní statistika (5. vyd.). Wiley. ISBN 0-471-61518-8.
externí odkazy



